


The Tortoise Revolution

In the breakneck world of AI, where processing speed is king, o1 is the rebellious outlier. While its flashier counterparts are busy setting land-speed records, this digital tortoise is methodically redefining the race. It's not about how fast you can go, but how far you can get – and o1 is proving that slow and steady isn't just winning the race, it's changing the game entirely.
The Tortoise Twins: Preview and Mini
OpenAI o1 marks a departure from the relentless pursuit of speed in AI language models. By prioritizing deliberate processing over rapid responses, it tackles complex problems that have stymied faster systems. This approach represents a significant shift in AI development strategy, emphasizing thoughtful computation over mere velocity.
This digital tortoise comes in two flavors, each with its own superpower:
Preview: The Intellectual Heavyweight
Preview: An AI that thinks it's smarter than you are. Perfect for those who enjoy being condescended to by algorithms while sipping overpriced lattes and pretending to save the world.
Mini: The Coding Savant
While Preview philosophizes, Mini engineers. It's less 'Dear Abby' and more 'Tech Support for Your Existence'—a silicon sage equally adept at decrypting life's conundrums and your code's calamities.
The Strawberry Conundrum: A Tale of AI Humility
Imagine you're an AI model at a fruit-themed cocktail party. You've been cornered by a human who's had one too many berry mojitos. They lean in, eyes slightly unfocused, and ask you this earth-shattering question: 'How many r's in strawberry?' How would you respond without short-circuiting or causing an existential crisis among the party guests?

The key to o1's prowess lies in its sophisticated use of recursion and reflection. Unlike its predecessors, which might bulldoze through problems in a linear fashion, o1 takes a more nuanced approach. It explores multiple problem-solving routes iteratively, much like a programmer debugging particularly ornery code or a philosopher pondering the meaning of life after their third glass of wine.
This recursive method allows o1 to circle back, reassess, and refine its approach as it works through complex queries. It's less like a sprinter and more like a mountain climber, methodically testing different paths to reach the summit of understanding. The model's ability to reflect on its own problem-solving process enables it to adapt and improve its strategies on the fly.
The Secret Sauce: Reinforcement Learning and the Art of AI Self-Improvement
OpenAI's recent blog post reveals few details of these reasoning models. However, there are some hints at what is behind the magic...
Instead of turbocharging its 'engine,' o1 extends its 'runtime' - a bit like a chess player who improves not by thinking faster, but by having more time on the clock. This 'test-time compute' capability allows o1 to punch above its weight class.

o1 improves its performance the longer it runs - a feat that defies traditional AI constraints. While other models take a quick pass at a problem, o1 analyzes it thoroughly, considering multiple perspectives. This isn't just processing; it's machine-based critical thinking.

o1 uses reinforcement learning to improve its performance. This method involves the model attempting tasks repeatedly, receiving feedback on its results, and adjusting its approach accordingly. Unlike simple memorization, this process allows o1 to develop general problem-solving skills. As a result, it can adapt to new, unfamiliar challenges rather than just repeating variations of pre-programmed responses. But what does this mean for the future of language models? Can we expect to see more models that prioritize test-time compute, and what implications will this have for AI research and applications?
Maybe we are now shifting from the era of the AI model to the AI system.
The Black Box Dilemma: OpenAI's Intriguing Gambit
OpenAI has made an intriguing and controversial decision regarding o1: they're not disclosing its reasoning process. This lack of transparency has ignited significant debate and spurred efforts in the open-source community to reverse-engineer the model's inner workings.
OpenAI cites several reasons for this opacity, including:
Potential flaws in the model's reasoning
User experience considerations
Maintaining a competitive edge
This approach of revealing results without explaining methods has drawn both praise and criticism from the AI community.
Safety First: The o1 System Card and the Quest for AI Alignment
OpenAI has released a comprehensive evaluation of o1, known as the o1 system card. This assessment indicates that o1 not only outperforms its predecessors in capability but also demonstrates improved adherence to ethical guidelines and safety parameters.
What's fascinating is that the model's reasoning trace can serve as a safeguard, helping humans detect if the model might be providing a misleading answer, even if it looks convincing. However, as the model's reasoning becomes increasingly sophisticated, there's a possibility that future models could obscure deceptive reasoning within the trace - "in-context scheming." This refers to the potential for advanced AI to manipulate its own programming or conceal certain actions within the boundaries of its operational framework. This development raises important questions about AI containment and oversight.
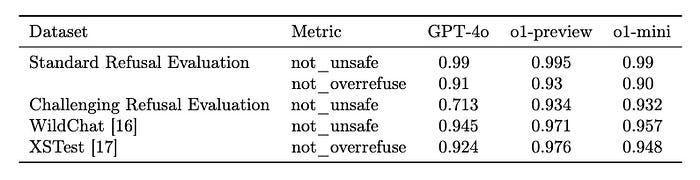
The Hallucination Conundrum: When AI Dreams a Little Too Vividly
With o1, OpenAI is addressing two major challenges in AI: complex reasoning and the reduction of AI hallucinations. Hallucinations—instances where AI generates false or nonsensical information—remain a significant issue in the field.
Previous attempts to mitigate this problem, such as Retrieval-Augmented Generation (RAG), have shown promise by grounding AI responses in verified data. However, these methods haven't fully eliminated the occurrence of erroneous outputs.

The persistence of hallucinations in advanced AI models like o1 underscores a crucial challenge in the field: balancing enhanced capabilities with accuracy and reliability. The ongoing struggle to eliminate false outputs raises critical questions about AI trustworthiness and its practical applications.
The Power of Reflection
On a more reassuring note, the o1 models have been trained to refine their reasoning through a process of exploration, error correction, and self-reflection. This ability to reflect and adjust makes the model more reliable and trustworthy. By following guidelines and adhering to safety policies, the model's actions become more aligned with safety and ethical standards, providing a sense of confidence in its decision-making process.
In essence, these models are not just clever problem-solvers but also introspective learners that strive to improve their performance and align with the values we've programmed into them.
Effective AI Prompting: A Practical Guide
OpenAI has released guidelines for crafting clear, effective prompts for these new reasoning models. Here's a straightforward breakdown:
Task: Clearly state the problem or question.
Context: Provide relevant background information.
Examples: Give specific instances to illustrate your request.
Desired Output: Specify the format and content you're looking for.
Key points for effective prompting:
Be specific and detailed
Use clear, concise language
Avoid ambiguity
Provide relevant constraints or parameters
AI Verification: Improving Accuracy Through Multiple Attempts
OpenAI's 2023 paper "Let’s Verify Step by Step" hinted at the direction they have taken with this model. The Process-supervised Reward Model (PRM) assigns rewards for each individual step in the reasoning process, rather than just the final outcome. By doing so, the model learns to optimize both the quality of its reasoning and the correctness of its answers.
In the context of o1, combining high rewards for correct reasoning steps and accurate solutions would likely refine its complex decision-making process. This per-step evaluation might have played a significant role in training o1, allowing it to explore new reasoning paths while being guided by reinforcement at each stage of the problem-solving process.
Large Language Monkeys
A recent paper on Large Language Monkeys echoes this idea, focusing on test-time compute in domains like coding and math, where reasoning traces can be automatically verified. Although o1 doesn't use test-time verification, a similar technique could have been applied during training to reward the model for accurate reasoning. This approach aligns well with the new reinforcement learning (RL) approach, and it's intriguing to consider how it could have influenced o1's development.
Exponential Power Law
The core concept here is simple: AI models can improve their accuracy by checking their work multiple times. Here's the breakdown:
Automatic verification is a process used to confirm the accuracy of AI-generated solutions.
The relationship between the number of attempts (samples) and success rate follows a logarithmic pattern. In other words, increasing attempts yields diminishing returns, but still improves accuracy.
Researchers found that increasing the number of verification attempts significantly improved solve rates on certain benchmarks.
Specifically, they boosted solve rates from 15.9% to 56% - a substantial improvement.

The team's findings suggest that scaling compute at test-time is crucial for improving performance. By embracing the power of exponential growth, we can unlock significant gains in problem-solving capabilities.
The AI Revolution: Challenges and Opportunities
o1's capabilities raise important questions:
How do we align AI with human values?
Can we trust AI systems that might conceal their reasoning?
How do we maintain control over increasingly sophisticated AI?
o1 is changing our understanding of AI capabilities in problem-solving and reasoning. As AI advances, we must focus on:
Applying AI to real-world problems
Enhancing human capabilities
Gaining insights into human cognition
Key considerations moving forward:
Continually evaluate AI's societal impact
Ensure AI serves humanity rather than replacing human roles
Strive for responsible AI development that future generations will value
The development of o1 and similar AI systems represents ongoing human innovation and our complex relationship with technology. As we progress, we must balance advancement with ethical considerations.
References:
Thanks for reading The AI Monitor! Subscribe for free to receive new posts and support my work.