

The Measurement Gap
Why AI ROI Remains Mostly a Matter of Belief
This article was originally commissioned by iX, the German magazine for professional IT, and published in German as the cover feature in the June 2026 issue, iX 06/2026. The original article, “Die Messlücke: Warum keiner weiß, was KI bringt,” appears on page 54 and is available from Heise here: [article link]. The full June 2026 issue is available here: [issue link].
It is republished here in English with the kind permission of Heise Medien GmbH & Co. KG.

Enterprise AI adoption currently rests more on assumption than on demonstrable evidence. Hardly anyone is measuring whether the investment pays off. Research findings, industry interviews, and observations from two major European industry events show that this measurement gap is structural in nature.
By Adam Mackay
Key points
AI adoption in German enterprises is rising sharply, but the value it delivers often remains unclear.
Productivity effects are rarely systematically measured, neither at the macroeconomic scale nor within enterprises.
In a randomised controlled trial, experienced developers were 19 percent slower with AI tools but believed they were 20 percent faster — calling self-reported productivity figures into question.
In talks and workshops with engineers at two European industry events, every participant reported using AI. None had formally measured its impact, however.
Enterprises across Europe are adopting AI at an accelerating rate and are not shy about saying so. Yet, with very few exceptions, they struggle to demonstrate that the investment is delivering returns. According to the Statistisches Bundesamt, the share of German enterprises using AI rose from 12 percent in 2023 to 20 percent in 2024 and reached 26 percent in 2025 (destatis.de/DE/Themen/Branchen-Unternehmen/Unternehmen/IKT-in-Unternehmen-IKT-Branche/Tabellen/ikti-unternehmen-kuenstliche-intelligenz.html). Eurostat shows a parallel trajectory at the EU level, with AI adoption at 13.5 percent of EU enterprises in 2024 and 20 percent in 2025 (ec.europa.eu/eurostat/web/products-eurostat-news/w/ddn-20251211-2).
A Bitkom survey of 604 German companies, published in September 2025, reports that 36 percent of enterprises use AI — the difference reflects methodological variation in how adoption is defined. The trend rises across all sources, but the distance between leadership claims and operational reality remains (Figure 1).
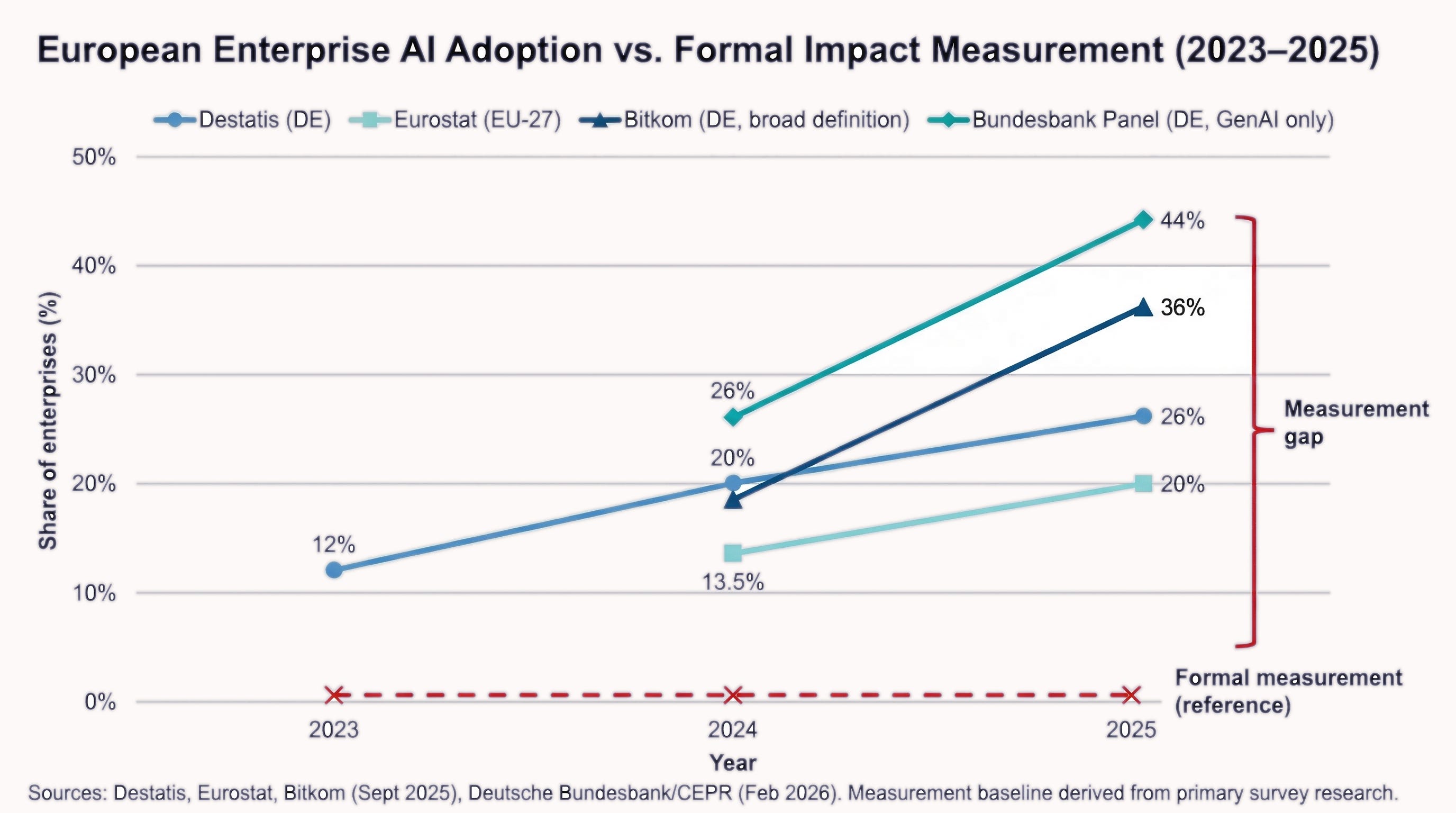
European enterprise AI adoption has accelerated sharply across all major survey sources (2023–2025), but the share of organisations formally measuring AI impact remains near zero (Fig. 1).
The global picture reinforces this trend. In March 2026, financial data company FactSet reported that 68 percent of S&P 500 companies cited AI in their fourth-quarter 2025 earnings calls (insight.factset.com/more-than-65-of-sp-500-earnings-calls-for-q4-cited-ai). This reflects US capital markets rather than European enterprise reality, but it sets the global tone for return-on-investment expectations.
That a certain lag exists between investment decisions and impact measurement is not unusual. The gap between AI rhetoric and measurable impact, however, points to a more fundamental problem: the preconditions for meaningful measurement do not exist in most enterprises, and several circumstances prevent them from emerging.
Everyone Uses AI, Nobody Measures the Effects
This pattern surfaced consistently at two major European industry events in early 2026 — the Embedded Testing conference in Munich in February and Embedded World in Nuremberg in March. Across conversations with professional software engineers working in embedded systems, industrial automation, and safety-critical domains, the finding was uniform: every engineer used AI tools, every one believed they helped, but not a single one had formally measured the benefit or could identify a colleague who had.
Bundesbank President Joachim Nagel laid out the macroeconomic picture clearly in a keynote at the International Economic Symposium in Rome on 21 April 2026 (bundesbank.de/en/press/speeches/already-here-not-yet-everywhere-shaping-the-economic-impact-of-artificial-intelligence-994048). AI’s capabilities are already visible across many applications, he noted, yet “its broader economic impact is still far less apparent from the aggregate statistics.” A February 2026 Deutsche Bundesbank study, published through the Centre for Economic Policy Research (CEPR), confirmed this finding (cepr.org/voxeu/columns/generative-ai-german-firms-diffusion-costs-and-expected-economic-effects). The study draws on data from the Bundesbank Online Panel, an extensive survey of companies.
Among respondents, the adoption rate climbed from 26 percent in 2024 to 44 percent in 2025, and yet “systematic firm-level evidence remains scarce” (bundesbank.de/en/bundesbank/research/survey-of-firms-bop-f), the study’s authors note. The measurement gap runs from the individual engineer’s desk to the central bank’s statistics.
Examining why this gap persists reveals three structural barriers: shadow AI, a confidence gap, and political economy (Figure 2).

Three structural barriers prevent the measurement of AI’s effects in enterprises: shadow AI generates invisible metrics, the confidence gap makes self-reports unreliable, and the political economy of non-measurement removes any incentive to ask questions (Fig. 2).
Shadow AI as the Common Denominator
The first barrier to measurement is visibility. To calculate impact, you need metrics: the scope and extent of AI usage must be known before its effects can be quantified. In most enterprises, the precise extent is unknown.
A targeted email survey by the author of experienced professionals across industrial manufacturing, medical devices, and academia made this plain. Three respondents from the same German manufacturer were asked to estimate the proportion of unauthorised AI usage in their organisation. Their answers ranged from 1 to 60 percent. When colleagues within the same company differ that widely on how much hidden AI usage exists around them, the foundation for any enterprise-wide metric is missing.
The pattern extends beyond large manufacturers. A professor at Friedrich Schiller University Jena described AI adoption in conversation as “decentralised organisation, mostly personal interest and own initiative.” When adoption is driven by individual curiosity rather than institutional strategy, it is invisible by definition. Over two-thirds of respondents cited the same primary reason for non-reporting: there was no incentive to report it, and nobody was asking. Measurement fails because the question is never posed.
Bitkom’s October 2025 survey on shadow AI in German enterprises quantifies the governance gap: the share of companies reporting widespread unauthorised AI usage doubled from 4 to 8 percent in a single year (bitkom.org/Presse/Presseinformation/Beschaeftigte-nutzen-Schatten-KI). Only 23 percent of respondents had established AI usage rules (up from 15 percent in 2024). Some governance-mature organisations have implemented central AI oversight, but the majority of enterprises lack even basic visibility into how their employees use AI tools. A further 24 percent of companies had not addressed the issue at all.
Even vendors with rules around their AI products encounter this dynamic. A vendor may specify governed data flows in its contracts, but it cannot govern the unauthorised tools that surround its product on the customer side. The governance boundary ends at the contract; the shadow AI problem does not. Without centralised infrastructure capturing which AI tools are used, by whom, and for what purpose, only an estimate remains.
The Confidence Gap
Where shadow AI concerns what cannot be seen, the confidence gap concerns what cannot be reliably measured. Self-reported productivity estimates are the primary measurement instrument available to most organisations, and studies show that they are systematically unreliable.
The most rigorous test of this question to date is a randomised controlled trial by METR (Model Evaluation and Threat Research), published in July 2025 (arxiv.org/abs/2507.09089). Sixteen experienced open-source developers, with over five years of contributor experience working on codebases exceeding one million lines of code, completed 246 real-world tasks with and without AI tools.
The result: developers were 19 percent slower when using AI assistance. Before the study, participants predicted AI would make them 24 percent faster; after the 246 screen-recorded tasks, they estimated it had made them 20 percent faster. The 39-percentage-point perception gap persisted despite direct experience with the measured outcome (Figure 3).
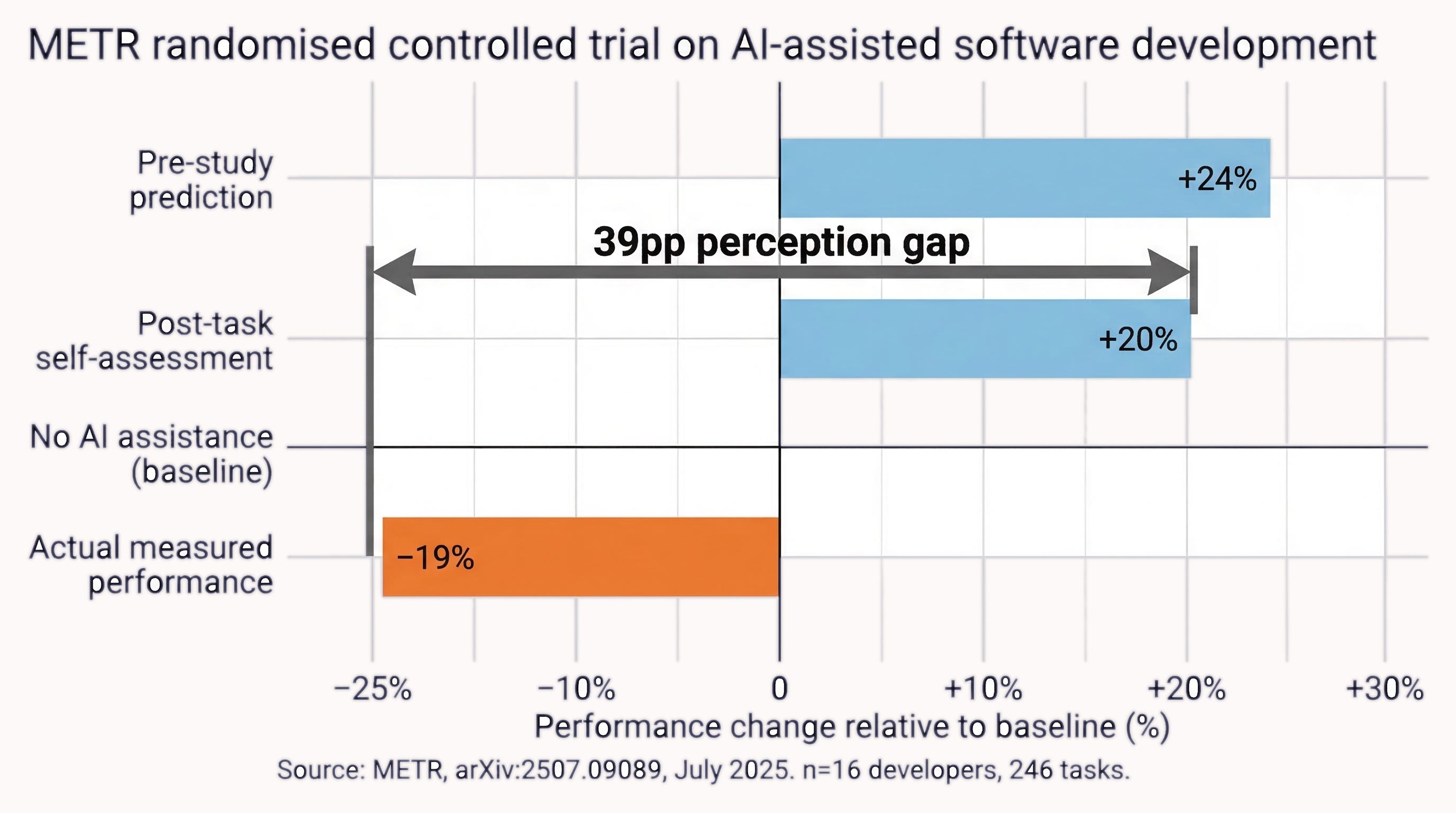
In METR’s randomised controlled trial (July 2025, n = 16 experienced developers, 246 tasks), actual AI-assisted performance was 19 percent slower than baseline, while self-assessment claimed 20 percent more efficiency — a 39-percentage-point perception gap (Fig. 3).
The METR researchers identified the decisive mechanism in the task structure itself: time gained while generating code with AI assistance was lost again while reviewing, correcting, and prompting the AI outputs. The speed gains were not eroded by external factors but by the review effort that AI usage itself created.
A February 2026 METR follow-up revealed a further complication: between 30 and 50 percent of developers approached for a replication study refused to participate unless they were allowed to use AI. This made controlled comparison impossible (metr.org/blog/2026-02-24-uplift-update/). METR acknowledged that AI tools had likely improved in the interim, but the methodological finding stands on its own: the population of developers willing to work without AI is shrinking. With it, the conditions for controlled measurement are eroding.
The confidence gap also extends to quality. Researchers at Stanford University found that developers with access to an AI programming assistant wrote significantly less secure code while being more likely to believe their code was secure (arxiv.org/abs/2211.03622). Researchers at New York University and the University of Calgary analysed 1,689 GitHub Copilot-generated programs across 89 security-relevant scenarios; approximately 40 percent contained vulnerabilities (arxiv.org/abs/2108.09293).
Both studies predate current-generation models, yet the finding remains relevant: the overconfidence effect is presumably structural rather than contingent on any particular model’s capability. AI-assisted work can falter in places that users do not perceive — a metric that captures only speed and overlooks quality, security, and maintainability produces false confidence.
Perception in Practice
This pattern reproduced at both industry events: at the Embedded-Testing conference in Munich, approximately half of the audience in a talk on AI productivity in software testing agreed by show of hands with a suggested 40 percent time-saving figure — an estimate every attendee believed reflected a genuine positive impact. The subsequent discussion revealed that no one in the room had a formal process to verify the estimate.
At Embedded World in Nuremberg, the picture was more cautious: in a software quality workshop, only around 10 percent of attendees initially agreed with an abstract 40 percent time saving. When one attendee rephrased the statement — “you can maybe do five days’ work in three days” — the mood in the room shifted abruptly: the abstract figure drew hesitation; described as a lived experience, it drew broad assent. That the very framing of the question influences the answer fundamentally undermines the reliability of any self-reported metric.
One experienced embedded systems test engineer also identified a methodological gap: the training and experimentation time required for effective use of AI tools is routinely excluded from productivity estimates. The headline savings assume the user is already fully proficient. In reality, the cost includes a continuous learning curve. Models and AI tools evolve rapidly; workflows built on one version may already be outdated by the next. This ongoing requalification effort should therefore be understood not as one-time overhead but as a continuous operational expense.
What the Experts Say
Patrick Stiller, who leads AI product strategy at tracetronic GmbH, a Dresden-based test automation firm, confirmed in an interview that even commercial AI product evaluation relies heavily on informal assessment: “We have customers with inhouse solutions who benchmark them against our product and assess quality metrics, but mostly by hand — meaning engineers just trust their gut feeling.” The result is that metrics for the value added by AI offerings are missing or are not tracked.
Stiller also identified a consequential dimension of the confidence gap, the expert-domain honesty problem: “People love AI when it handles things they can’t. But when it comes to their own field of expertise, the reaction regarding the achieved time savings and the quality is noticeably more reserved.” When AI assists in an unfamiliar domain, the user readily credits it. When AI assists in their own field of expertise, it feels like an admission of incompetence. The result is a systematic reporting bias that few survey methodologies can fully correct.
Ulf Schmelzer, Product Owner and Line Manager at dormakaba Deutschland GmbH, described a pattern that illustrates the gap between gross and net productivity in practice: “Coding is faster, but the review takes longer, which sometimes puts one in the net minus.” This observation matches what METR measured experimentally — now from the perspective of daily work. The productivity figure that circulates within the organisation reflects only the first half of the equation.
Laurent Pascou, a functional safety expert, made an important point: “AI-generated material should only be an initial version. The starting point should be sound requirements definitions validated by dedicated tools before they are used as input to AI tools. After the automatic generation of initial code and test cases, real people should continue the work through to project finalisation. Besides semantic unreliability, this would prevent another critical aspect: complexity overflow. Without control, AI tools can generate code too complex to be read, understood and maintained by human developers.”
Hidden Technical Debt
When AI output requires substantial human refinement — and a robust process requires precisely that — the net time saving is significantly lower than the gross figure, since most self-reported estimates capture only generation, not the full cycle of review, correction, and integration. Even when AI results pass immediate quality checks, they may produce maintenance burden that surfaces only months or years later.
In safety-critical domains (automotive ECUs, medical devices, industrial control systems), the consequence is not merely maintenance cost but potential safety incidents when opaque AI-generated code fails under edge conditions that no reviewer anticipated.
Pascou was careful to balance this view: “On the other hand, AI would be especially useful in other areas of safety-related software development — for instance in the formal validation of code, such as AI-driven execution of Frama-C.” Frama-C is a framework developed in France for analysing C programs.
In the email survey mentioned earlier of professionals from manufacturing, medical devices, and academia, all participants who estimated productivity gains placed them in the 10 to 20 percent range. Asked what these estimates were based on, the answers fell into two categories: anecdotal observation or general impression. Not a single respondent had drawn on formal measurement, controlled baselines, or before-and-after comparisons. A senior development professional from a medical devices firm, whose organisation had integrated AI across all engineering workflows, was the only one to observe that “people consistently overestimate the gains.”
The Political Economy of Non-Measurement
The third structural barrier is political in nature. Organisations have rational reasons not to measure AI’s effects. Individuals within organisations have equally rational reasons not to disclose their own AI usage.
When asked whether enterprises would welcome full visibility into AI usage and its measurable impact, not a single respondent answered yes. The answers were: “not ready to act on what the data would show,” “the political implications would be unwelcome,” and “no appetite for this level of transparency.”
Individual motives reinforce this reluctance. Anyone reporting that AI made a task 60 percent faster invites the question of whether the role still needs to exist at its current scope. Stiller confirmed this: “We are observing a cognitive bias here: the value of a solution is often judged by the effort invested rather than its actual utility.” The result is a systematic shortage of reports on AI assistance in expert domains — out of understandable self-interest.
Technical barriers are solvable, and methodological biases can be identified through careful study design. The political economy of non-measurement, however, operates at the level of organisational culture and career incentives. It persists for as long as there is no pressure in the other direction. One engineering lead from industrial embedded systems summed up the reporting culture: “People use AI tools but tend not to advertise it.” The measurement gap is not solely a failure of infrastructure or methodology. It is in significant part a feature of rational behaviour within existing organisational structures.
Structural Implications for IT Leadership
Even where AI products are deployed under regulated contracts, on-premises installations and data sensitivity typically separate vendor data from customer data. The most reliable signal available to vendors is consumption volume (token usage, credit drawdown). It confirms that a product is being used but says nothing about whether it delivers value.
Customer evaluation, multiple interviewees reported, collapses to a binary decision: continue with the product or not. What the AI market calls “impact data” is in practice adoption and churn data: consumption volume, licence renewals, feature activation. These are indicators of satisfaction, not measures of outcome.
Customer-side impact measurement is still in its early stages. Several vendors and industry players are developing metric frameworks for quality benchmarks and traceability, but these efforts remain fragmented — an indication of how far the field is from established, consolidated measurement standards.
A structural dilemma compounds this, as one experienced engineering lead at a mid-sized German manufacturer noted with reference to a specific AI tool in his company: “The problem is that the circle of users is small. So the impact is probably too small for the measurement to be worthwhile.” What he describes for a single tool applies structurally to pilot projects in general: without measurement, scaling cannot be justified; and without scaling, the user base remains too small to justify building measurement infrastructure.
Another senior engineer pointed to the underlying problem: “High volatility in development time and the influence of other ongoing optimisations.” In a development environment where multiple improvements run in parallel, isolating AI’s specific contribution is methodologically difficult even when the will to measure exists.
Compliance Without Evidence of Impact
Alongside the technical hurdles, an extensive compliance apparatus has emerged in recent years. ISO 42001, the NIST AI Risk Management Framework and the EU AI Act all require documented processes for risk management, data quality and organisational accountability. These frameworks have a clearly defined purpose — controlling risk and securing governance — and they deliver standardised evidence to that end.
In practice, however, this produces a shift in attention. Where compliance documentation already satisfies most of the formal reporting obligations to the board, regulators and auditors, many organisations feel no additional pressure to measure the impact of their AI investments in parallel. Impact measurement has to be funded separately, set up separately, and sustained over months — and when resources are finite, the mandatory work wins. The result is an organisation that can prove its frameworks were correctly implemented, but not that its AI investment has generated a return.
A systematic review by researchers at Stanford University and Montclair State University examined 84 published AI evaluation papers from the years 2023 to 2025 (arxiv.org/abs/2506.02064). Of these, 83 percent included technical performance metrics — the study’s authors list task success rate, accuracy, latency, and throughput as typical examples. Such measures show how well a model solves an isolated task, not whether its use in a working context creates value. User-centred measures such as trust, usability, or workflow integration appeared in only 30 percent of the papers, and a mere 5 percent contained any long-term evaluation. The authors cite evidence that “realised returns are often less than 25 percent of forecasts.”
This means organisations may be capturing less than a quarter of the expected benefit. The academic evaluation apparatus reproduces this measurement gap by favouring convenient technical metrics over the user-centred measurements and economic assessments that would reveal whether AI delivers sustained value.
Conclusion
Genuine impact measurement of enterprise AI usage requires structures that most organisations have not yet established and many deliberately do not want to establish. Centralised AI infrastructure must capture which tools are in use and who uses them for which tasks and at what volume. Usage telemetry must distinguish between productive use and experimentation, as well as between authorised and unauthorised tools.
Controlled baselines must allow comparison of work outputs with and without AI assistance. Long-term measurement must extend over months and years and include downstream consequences such as maintenance burden, technical debt, and security vulnerabilities. Each of these conditions is achievable on its own; together they constitute an investment that most organisations are not yet prepared to make and some actively avoid.
The gradual closing of the measurement gap begins with practical steps. The most effective is to make official AI tools available to all teams through central channels, since usage that flows through governed infrastructure becomes automatically visible. With that, the shadow AI problem loses its breeding ground.
Investing in continuous AI training removes a blind spot: acknowledged training time produces more honest reporting than informal self-teaching. It makes sense to build measurement programmes alongside AI pilots from day one, rather than searching for evidence after the fact. Only when AI usage measurement is separated from individual performance evaluation does the psychological safety needed for sincere feedback emerge; with it, the expert-domain honesty problem also loses its sharpness. It is also advisable to standardise metrics across teams before aggregating results. This avoids fragmentation caused by different usage in different teams.
The measurement gap is a composite of invisibility (shadow AI), unreliability (the confidence gap), and deliberate non-inquiry (the political economy of non-measurement), reinforced by compliance frameworks that favour process documentation over impact measurement. Enterprises that want to move beyond anecdotal evidence must build measurement infrastructure early and accept what the data shows, regardless of its political convenience.
Author
Adam Mackay is Head of AI at QA-Systems and co-author of Embedded Software Testing (BPB, 2026). He has 28 years of experience in safety-critical systems.
My thanks to the editors at iX and to Heise Medien GmbH & Co. KG for commissioning the original article and for permission to republish this English version. You can read the original German version on Heise here: [article link], and view the full iX 06/2026 issue here: [issue link].