

When Will AI Become Transformative? Leading Experts Disagree
When Will AI Become Transformative? Leading Experts Disagree
Understanding the Key Debates on AI Timelines


In my years navigating the realms of artificial intelligence, a question perpetually presents itself: when will AI leap from its current state to become a transformative force? This inquiry, far from idle speculation, is crucial in shaping our approach to a future interwoven with advanced AI technologies.
In a thought-provoking article I recently stumbled upon, a range of expert opinions painted a diverse picture of AI's potential timeline. Some voices echoed caution, predicting a steady, gradual evolution. Others, brimming with optimism, forecasted a rapid, revolutionary change.
The article here, involves contrasting views from three distinguished experts, each with a unique perspective on AI's trajectory.
Leading the discourse are three prominent figures: Ajeya Cotra from Open Philanthropy, Daniel Kokotajlo from OpenAI, and Ege Erdil from Epoch. Their backgrounds in AI research and policy lend weight to their projections. Cotra, with a rich blend of technical and societal analysis, places the median timeline for automating 99% of fully remote jobs at 2037. Kokotajlo, whose work focuses on forecasting AI's trajectory and preparing for its risks, sees this milestone arriving much sooner, by 2027. Erdil, offering a more conservative perspective, extends this prediction to 2077. The span of these estimates, despite extensive research and expertise, highlights not only the complexity of AI's development but also the crucial uncertainties that frame our future.
These disparities are further underscored when we consider their views on humanity's energy consumption, a key indicator of AI's scale and impact. Daniel envisions a future where we use energy equivalent to powering ten modern-day countries within just 15 years. Ajeya extends this timeline to 30 years, and Ege projects it to over 150 years. Such vast differences in predictions underscore the need to understand the underlying assumptions and methodologies guiding these forecasts.
The experts' dialogue, spanning three hours and facilitated by Habryka from the Alignment Forum, delved into these contrasting views. The discussion initially centered on the differing perspectives between Daniel and Ajeya, gradually incorporating Erdil's stance. This structured conversation, summarized by Habryka, brought to light key areas of agreement and disagreement.
In this exploration, we will delve into the compute-focused forecasting methodology shared by Daniel and Ajeya, examining its foundations and implications. We'll also navigate through the areas of contention, such as the capabilities of transfer learning and the concept of AI accelerating its own research and development. Additionally, the discussion will cover the median scenarios described by each expert and their implications, providing a multifaceted view of what lies ahead in the realm of AI.
With this groundwork laid, let's step into the world of compute-focused forecasting and its role in shaping the debate on when AI will become a transformative force in our lives.
The Compute-Focused Forecasting Approach
Exploring the intricacies of AI forecasting reveals a shared methodology between Ajeya and Daniel, hinged on the pivotal role of computing power. This approach, deeply rooted in the quantifiable metrics of computational evolution, proposes a tangible framework for anticipating AI's transformative milestones.
Central to their method is a comprehensive assessment of compute requirements for advanced AI. This encompasses not only the predicted growth in computing power but also the potential for algorithmic efficiency improvements. This multi-faceted model provides a more grounded and measurable way to navigate the otherwise speculative terrain of AI development.
Tom Davidson's model is a prime illustration of this approach. It meticulously tracks two pivotal variables: the rate at which computing power for AI training and inference doubles – approximately every 3.4 months – and the rate of algorithmic progress, which effectively halves the compute needed for training a model of a given size every 1.3 years. These metrics offer a concrete foundation for forecasting AI's trajectory, linking computational advancements directly with AI capabilities.
This method also considers factors like FLOPs needed to match human brain capacity, compute needed per unit of experience, and training task horizon lengths. Such detailed analysis helps in distilling the expansive and complex domain of AI development into more understandable components.
Historically, this compute-focused approach has precedents, such as Moravec's 1988 prediction about AI matching human intellect by 2010. This history lends credibility to the approach, suggesting that its reliance on computational trends isn't a novel idea but one with historical grounding.
However, there are notable limitations. The approach often overlooks real-world deployment challenges and the hardware constraints that can impede rapid development. The limits of data availability also pose significant hurdles. These factors, along with the unpredictability of theoretical breakthroughs, add layers of complexity to the forecast.
Ege Erdil adds a crucial perspective, emphasizing the uncertainties inherent in such models: "We don't know what we don't know." His words succinctly capture the unpredictability of AI's trajectory, reminding us of the potential gaps in our understanding and forecasting.
The model's reliance on observable compute trends offers a significant advantage. By anchoring predictions in measurable and evolving trends, this approach provides a more solid foundation compared to abstract theoretical reasoning. It taps into a history of technological growth, offering a practical lens through which to view future developments.
Maintaining a balanced and objective tone, it's clear that while this compute-focused approach offers a solid foundation, it's not without its debates and uncertainties.
In the forthcoming section, we'll explore the key areas of contention, diving into the nuances of transfer learning capabilities, AI's potential to self-accelerate R&D, and more. This transition will illuminate the diverse perspectives that define the debate on AI's future timelines.
Key Areas of Disagreement
Before diving into their divergent views, let's clarify some concepts: transfer learning and compute overhangs. These form the backbone of our discussion.
Transfer Learning Explained
Transfer learning in AI refers to the ability of a model to apply knowledge learned from one task to perform another, different task. It's akin to a person using math skills learned in school to solve real-world problems. The effectiveness of transfer learning determines how quickly and efficiently an AI can adapt to new tasks.
Disagreement on Transfer Learning
Ajeya and Ege are cautious about expecting breakthroughs in transfer learning soon, viewing it as a distant goal. This skepticism underlies their belief that AI’s impact on the economy and its self-improvement will be gradual. Conversely, Daniel does not see transfer learning as a critical factor at present. Essentially, the debate centers on how soon transfer learning will significantly impact AI development.
Compute Overhangs Unpacked
A compute overhang occurs when the existing computational power exceeds the current needs for AI development. It's like having a powerful engine in a car that's only driven in low-speed zones. This surplus has implications for how quickly AI might reach significant milestones.
Debates Around Compute Overhangs
Daniel views the current compute overhang as a potential accelerator for reaching AGI. Ajeya, however, believes AGI might emerge after this overhang is utilized. This divergence hinges on how they perceive the role of existing compute resources in accelerating AI’s growth. In essence, they disagree on the timing and impact of compute overhangs on AI's trajectory.
Hofstadter’s Law and AI Forecasting
Before discussing disagreements, let’s understand Hofstadter’s Law. It humorously asserts that tasks always take longer than expected, even when delays are anticipated. This law questions the accuracy of forecasting timelines, especially in complex fields like AI.
Interpreting Hofstadter’s Law
Daniel's stance minimizes Hofstadter’s Law in AI trend extrapolation, suggesting it adds only a few years to forecasts. Ajeya and Ege, however, advocate for a conservative approach, arguing this law could extend AI development timelines significantly. The crux here is whether Hofstadter's Law materially impacts AI forecasting.
AI Accelerating Its Own R&D: A Closer Look
As for AI catalyzing its own research and development, Daniel envisions AI as a significant accelerator in the near future. Ajeya perceives practical deployment challenges that could slow this process. Ege shares this cautious view, assigning a low likelihood to AI autonomously driving its R&D shortly. The heart of their disagreement lies in how soon AI will substantially speed up its own development.
Unifying the Disagreements
Each of these disagreements paints a vivid picture of the intricacies involved in forecasting AI’s future. Whether it's the potential of transfer learning, the implications of compute overhangs, the interpretation of Hofstadter’s Law, or the timeline for AI to self-accelerate its R&D, these debates underline the multifaceted nature of predicting AI’s trajectory.
These disagreements aren't just academic. They profoundly influence how we prepare for and shape our AI-driven future.
Scenarios for the Future
In our examination of the future through the lens of AI, we find ourselves facing diverse scenarios. These projections, crafted by Daniel, Ajeya, and Ege, offer us glimpses into potential futures that range from the imminent to the distant. Let's take a closer look at these scenarios, each weaving together technology and time.
Daniel's Vision: A Near-Future Transformation
Daniel foresees a future arriving sooner than many anticipate. His median scenario posits the advent of Artificial General Intelligence (AGI) by 2027 – a mere four years from now. This rapid timeline implies transformative changes almost at our doorstep.
But there's more. Daniel predicts a staggering increase in our energy consumption – a 1000x surge by 2042. This projection isn't just a number; it's a symbol of the immense scale and impact of AI. It suggests a world where AI's footprint on our resources and infrastructure becomes not just noticeable but overwhelmingly significant.
Ajeya's Forecast: A Measured Approach
Ajeya, on the other hand, envisions a more gradual ascent of AI. Her median scenario places the arrival of AGI by 2037. This slower timeline offers a different narrative – one of incremental progress and adaptation.
Similarly, Ajeya's perspective on energy usage aligns with her timeline for AGI. She projects the 1000x increase in energy use by 2057, reflecting a more measured and possibly manageable growth in AI's influence on our resources.
Ege's Projections: A Long-Term Perspective
Ege presents a markedly different view. He predicts AGI's emergence by 2065, suggesting a much slower and more evolutionary path for AI. In his scenario, we're not sprinting into an AI-dominated future; rather, we're walking steadily, allowing more time for understanding and integration.
His projections for energy use further underscore this gradual approach. Ege sees the 1000x increase happening well after 2150, painting a picture of AI growth that stretches far beyond our current horizons.
Comparing Their Visions
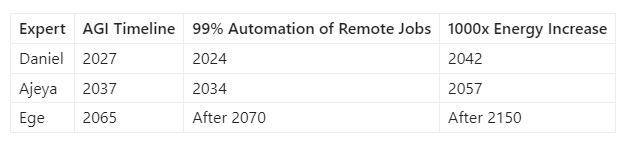
This table crystallizes the divergent paths AI might take according to these experts. It's a vivid illustration of how timelines can vary dramatically, even among those deeply immersed in AI's complexities.
Conclusion
In reflecting on the insights and predictions of these experts, a few key points stand out. Firstly, it's important to recognize the immense effort and expertise that underpin these forecasts. Hundreds of hours of analysis, discussion, and contemplation have been dedicated to them. Yet, substantial disagreements remain.
Understanding their reasoning is vital. It's not just about the forecasts themselves but about the thought processes and methodologies that shape them. The compute-focused approach, for instance, offers a useful anchor amidst the sea of uncertainties, but it's not without its limitations.
The key areas of disagreement we've explored – transfer learning, compute overhangs, Hofstadter's Law, and the self-acceleration of AI's R&D – highlight the complexity and nuance inherent in predicting AI's future.
As concrete milestones are reached and advances made in the coming years, they will illuminate the path AI is taking. These forecasts, in all their diversity, play a crucial role in how humanity prepares for an AI-integrated future. They challenge us to think, plan, and innovate with an open and balanced perspective.
Let's embrace the unknowns, prepare for the possibilities, and shape a future where AI's transformative power is harnessed for the greater good.